So whenever you search in google or amazon, whenever you start to type, it will immediately show you list of options in the search result. You can either select one from the list, or you can continue typing it will update with the relavent list.
So in this system design tutorial, we shall look at how to populate the list of relavent result once the user starts typing.
A simple solution to solve this is by using TRIE data structure. TRIE DS will provide time complexity of O(n) where “n” is the length of prefix. But how to scale this?
So basically on a high level, we can divide the logic into 2 parts:
1. Response Flow
2. Data gathering flow.
Part 1:
Response Flow: In this flow, you get a prefix from the user, you look into the distributed TRIE and return the auto complete for that prefix.
Data gathering flow: In this flow, we get the requests from the user by using a background process and save it in the TRIE DB so that it can be used later.
We shall discuss on how to implement both of these features below:
1. Response flow:
In this flow, the user types an alphabet we shall return the matching words from the TRIE DS.
For example: When user types in “a” it will first display “ant” followed by “anthem” as shown below:
ant
anthem
anti
antiquity
So how does the search engine know “ant” is the most used word starting with the letter “a” ?
For that we need to add additional data in TRIE called as “key” for every prefix for every node. Key is nothing but a list of words that are popular with that node.
For example: In node “a” the terms “ant” and “anthem” are very popular, we store it in node “a”.
similarly for the term “an” the top words can be “ant” and “anti”.
The top words for that prefix can be found out by the “Data gathering flow”.
Why are we storing the top terms in the nodes? This is because, when the user just enters “a” we can quickly look into the data and display the relevant result.
So if we start keepon adding the words, the TRIE will become very huge. This will pose a problem for durability and scalability.
Now let us see how to make the “Response flow” scalable.
Suppose we have just started the search engine, we dont have any data, hence we can store all the data into one single DB.
In our example we have 3 app servers. All the server will have the same data, for fault tolerance we have taken 3 servers.
Then in the zookeeper, we store the information like any request from “a to z” comes to the server, it should go to the app server “as1” or “as2” or “as3”.
Simple desing will be as shown below:
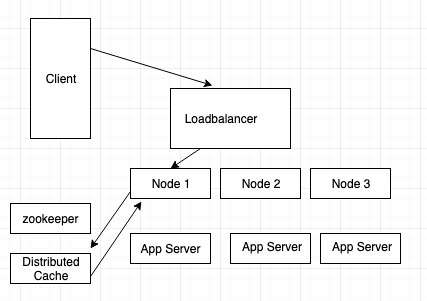
In the above structure we have the following components:
1. A load balancer
2. Nodes to server the request
3. Zookeeper
4. Distributed Cache
5. App server holding the data
So whenever user makes a new request, below steps will be followed:
1. The request will be first recieved by load balancer.
2. Load balancer will send to any one of the server nodes.
3. The server nodes will check with distributed cache to check if the query is there in the cache server.
4. If it is not there, it will go to zookeeper and check the range of the query and from which server the response to be taken. As of now we have only one range.
5. It will fetch the data from the respective server and display the result to the user.
6. The node will also store the result the result in memcache, so that in future if there is any new request with the same data, it can be fetched easily.
So now the new website is recieving more traffic and we need to scale up the system. How do we do that?
So instead of inserting all the data into one server. We split the range into 3 parts and assign to 3 different servers.
Example:
Server 1, 2, 3 will hold the data from a to i
Server 4, 5, 6 will hold the data from j to q
Server 7, 8, 8 will hold the data from r to z
Hence a user searching for the word starting from the prefix “j”, the query will go to the server 4 or 5 or 6.
Part 2:
2. Data gathering flow.
In this part we shall look on how to gather the data from the user and save it in our database for further processing.
So whenever a user searches for a term, we take that word and save it in an intermediate database called as aggregrator database. The database will start populating the data and keeps the data in a sorted format. Once the data in tha aggregator database reaches a certain threshold, the data will be transffered to the original application server database. We do this to reduce the load on the application server.
So while inserting the data, we insert “word” “time” and “weight”. The reason we save the time is because we need to give the user that is relavent and latest.
For example: Today is the final cricket match between 2 teams. So when the user searches for india vs australia, we need to comeup with the latest match result i.e related to cricket score.
And after 2 days, if there is any new big business deal between india and australia, when the user searches for “india vs australia” phrase, we need to come up with the business deal result.
So this completes our system design for auto complete search box. If you have any different idea of implementation please write it in the comment box below.